过去几年,人工智能(AI)从一个被轻视的学术冷门研究突然爆红,一路狂奔到商业化的最前沿,在安防、金融、教育、制造、家居、娱乐等各个与我们正常的生活息息相关的领域掀起了一股智能化升级和万物互联的飓风。
这场前所未有的技术革命的直接推动者,是国外谷歌微软Facebook、国内BAT等互联网巨头以及一众新生的AI初创企业,而这一些企业快速在AI领域开疆辟土的灵魂支柱,则是提供源源不断高密度计算能力的AI硬件提供商。
AI硬件应用场景通常分为云端和终端,云端主要指大规模数据中心与服务器,终端包括手机、车载、安防摄像头、机器人等丰富的场景。
无论是在线翻译、语音助手、个性化推荐还是各种降低开发者使用门槛的AI开发平台,但凡需要AI技术之处,背后都需要云端AI芯片夜以继日地为数据中心提供强大的算力支撑。
根据NVIDIA在2017年亮出的数据,到2020年,全球云端AI芯片的市场规模累计将超过200亿美元,这个体量庞大的市场已成为各路芯片巨头虎视眈眈之地。
NVIDIA通用图形处理单元(GPGPU)即是乘着深度学习的东风扶摇直上,股价在2015年还是20美元,到2018年10月飙升至292美元,市值超过肯德基和麦当劳,一跃成为AI领域第一股,市值数十亿美元,坐享无限风光。
其火箭般的涨势惊醒了一众潜在竞争对手,风暴出现在地平线上。半导体巨头英特尔、AMD等奋起直追,谷歌、亚马逊、百度、华为跨界自研,还有数十家新生芯片创企揭竿而起,意图通过自研架构等方式突破云端AI芯片性能的天花板,重塑这一市场的版图。
本文将对云端AI芯片的战事进行全景式复盘,盘点加入战局的五大半导体巨头、七大中美科技巨头和20家国内外芯片创企,看曾经缔造神话的NVIDIA,能否维系它的传奇帝国?如今已然浮现或者正在开发的新计算架构,能否适配未来的算法?哪些企业更有望在强手如林的竞争环境中生存下来?
谁能主导这场云端AI芯片战事,谁就掌握了将在未来云计算和AI市场的战役中赢得更多话语权。
十几年前,英伟达(NVIDIA)在经历过和数十家对手的激烈厮杀后,和AMD成为图形显卡领域的两大霸主。那时,大多数NVIDIA员工们,并不知道人工智能(AI)是什么。
彼时,NVIDIA总营收规模约30亿美元,其创始人兼CEO黄仁勋做了一个冒险的决定——每年为CUDA项目砸5亿美元,通过一系列改动和软件开发,将GPU转化成更通用的计算工具,累计总额近100亿美元。
这是一个极具前瞻性的决定。2006年,全球首款GPU上的通用计算解决方案CUDA现世,这一技术为编程人员带来越来越方便的入门体验,逐渐为NVIDIA GPU积累了强健稳固的开发者生态。
这一年,加拿大多伦多大学教授、机器学习领域泰斗、神经网络之父Geoffrey Hinton带领课题组用GPU训练卷积神经网络(CNN)AlexNet,一举拿下ImageNet图像识别比赛的冠军,将AI推到了学术界焦点的历史性拐点。
GPU并非为深度学习而生,其并行计算能力竟与深度学习算法的逻辑一拍即合。每个GPU有数千个内核并行,这些核心通常执行许多低级的、繁复的数学运算,很适合运行深度学习算法。
之后,越来越强的“CUDA+GPU”组合,凭借无敌的处理速度和多任务处理能力,迅速俘获一大批研究人员们的芳心,很快就成为全世界各大数据中心和云服务基础设施的必备组件。
NVIDIA在通往更强的道路上一往无前,陆续展示令人惊叹的Tensor Core、NVSwitch等技术,不断打造新的性能标杆。此外,它还构建了GPU云,使得开发者随便什么时间都能下载新版的深度学习优化软件堆栈容器,极大程度上降低了AI研发与应用的门槛。
就这样,NVIDIA靠时间、人才和技术的积累,垒起了坚不可摧的城墙。想要城池者,无不需要遵循NVIDIA指定的法则。截至今日,NVIDIA的工程师军团已逾万人,其GPU+CUDA计算平台是迄今为止最为成熟的AI训练方案,吞食掉绝大多数训练市场的蛋糕。
从功能来看,云AI芯片主要在做两件事:训练(Training)和推理(Inference)。
训练是把海量数据塞给机器,通过反复调整AI算法,使其学习掌握特定的功能。这样的一个过程需要极高的计算性能、精度和通用性。
推理则是将训练好的模型拿来应用,它的参数已经固化,也不需要海量数据,对性能、精度和通用性的要求没有训练那么高。
GPU在训练市场的是一座难以翻越的高山,但在对功耗要求更高的推理市场,它的优势相对没那么明显。
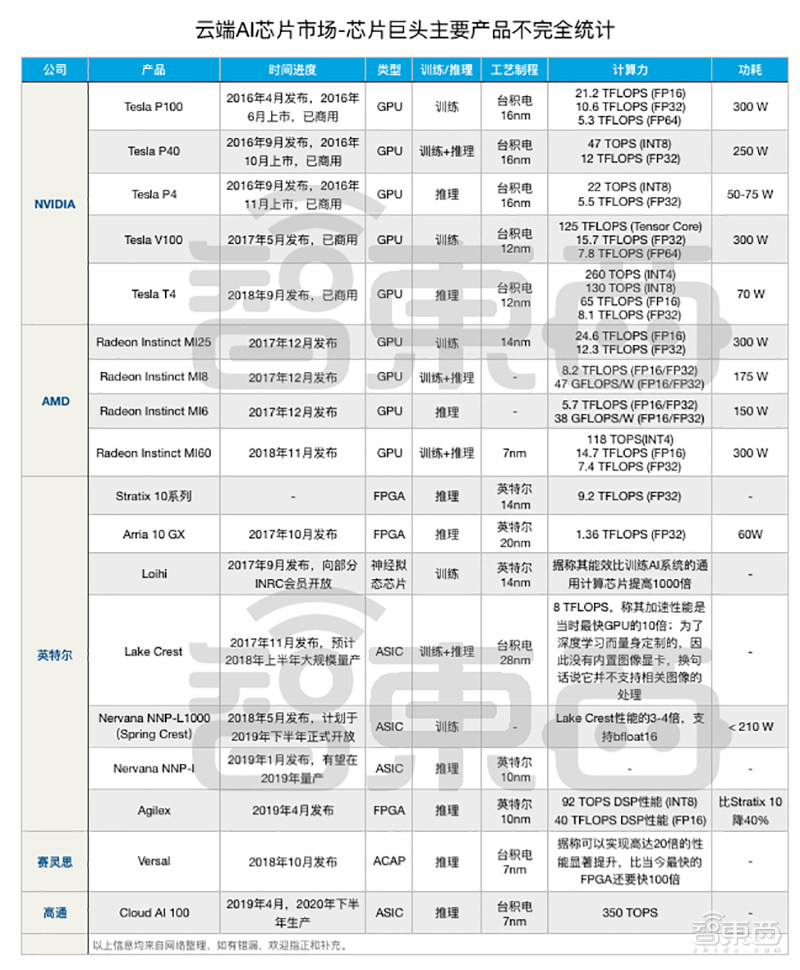
芯片是赢者通吃的市场,云端AI芯片亦不例外,NVIDIA为加速数据中心应用推出的高中低端通用GPU,一直是各路玩家参考的性能标杆。
NVIDIA在短时间内投入数十亿美元动用数千工程师,于2016年推出了第一个专为深度学习优化的Pascal GPU。2017年,它又推出了性能相比Pascal提升5倍的新GPU架构Volta,神经网络推理加速器TensorRT 3也同期亮相。
在最新季度财务报表中,NVIDIA数据中心收入同比增长58%至7.92亿美元,占公司总收入的近25%,在过去的四个季度中总共达到了28.6亿美元。如果它能够保持这种增长,预计2019年的数据中心将达到约45亿美元。
和NVIDIA在GPU领域长期相争的AMD,亦在积极地推进对AI加速计算的研发。2016年12月,AMD宣布主打AI与深度学习的加速卡计划——Radeon Instinct。

说起来,AMD在深度学习领域的起步离不开中国公司的支持。百度是第一家在数据中心采用AMD Radeon Instinct GPU的中国公司,后来阿里巴巴也跟AMD签了合同。

除了提供GPU芯片,AMD也在通过推出ROCm开放软件平台等方式构建更强大的开源机器学习生态系统。
虽说GPU暂时还抗不过NVIDIA,不过AMD有自己独特的优势。AMD既有GPU又有CPU,可以在其GPU与CPU间用Infinity Fabric实现无缝连接,而英特尔至强处理器+NVIDIA GPU就很难做到这样的完美连接。
在去年年底,Imagination高管在接受媒体采访时透露,Imagination可能会宣布推出面向AI训练的GPU。
在AI推理的应用当中,FPGA相较专用集成电路(ASIC)具有灵活可编程的优势,它们能针对特定的工作进行即时重新配置,比GPU功耗更低。
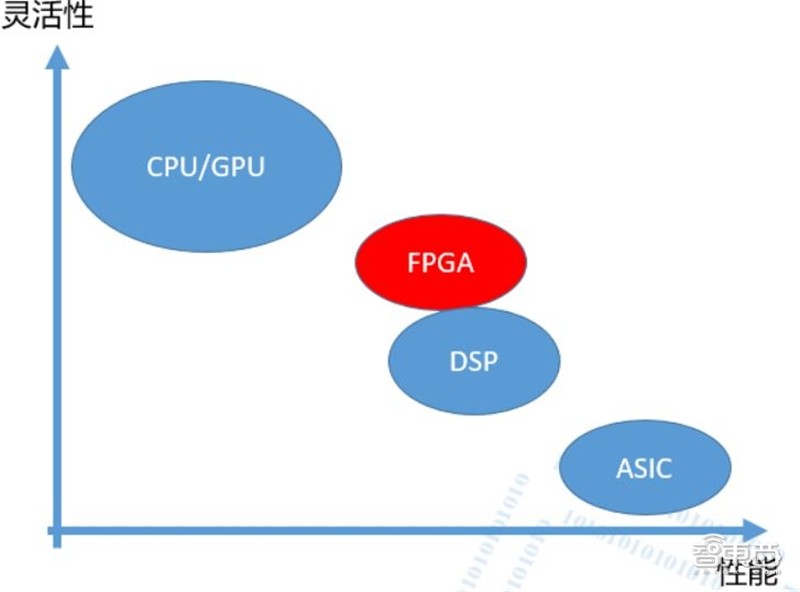
FPGA领域的老大老二常年是赛灵思和英特尔Altera,面对新兴的AI市场,体内的创新基因亦是跃跃欲试。
赛灵思即将上线的大杀器叫Versal,这是业界首款自适应计算加速平台(Adaptive Compute Acceleration Platform ,ACAP),采用台积电7nm工艺,集成了AI和DSP引擎,其软硬件均可由开发者进行编程和优化。
这一杀器用了4年的时间来打磨,据称Versal AI Core的AI推断性能预计比业领先的GPU提升8倍。按照此前赛灵思释放的消息,Versal将在今年发货。

如果说NVIDIA打开AI的大门,靠的是天然契合的基因,那么英特尔则是靠“买买买”的捷径,快速跻身云AI芯片的前排。作为几十年的半导体霸主,英特尔一出手目标就是成为“全才”。
众所周知,英特尔屹立不倒的王牌是至强处理器。至强处理器犹如一个智慧超群的军师,运筹帷幄,能处理各种任务,但如果你让他去铸造兵器,他的效率则完全比不过一个头脑简单但有一身蛮力的武夫。
因此,面对拥有大量重复性简单运算的AI,让至强处理器去处理此类任务既是大材小用,结果又很低效。英特尔的做法是给至强处理器搭配加速器。
2015年12月,英特尔砸下167亿美元买走当时的可编程逻辑器件(FPGA)的前年老二Altera,如今英特尔凭着“Xeon+Altera FPGA”异构芯片的打法,将数据中心某些任务提速十倍有余。
尤其是近一年来,英特尔对FPGA的加码肉眼可见。前两年,英特尔陆续推出号称是史上最快FPGA芯片的Stratix 10系列,这一系列获得了微软的青睐。
除了Stratix 10 FPGA芯片外,英特尔先是去年12月在重庆落户了其全球最大的FPGA创新中心,后又在今年4月亮出被悄然打磨了数年的新武器——全新架构的FPGA Agilex,集成了英特尔最先进的10nm工艺、3D封装、第二代HyperFlex等多种创新技术。

英特尔的FPGA已经在服务器市场初步站稳脚跟,而另一项重要的交易还处于蛰伏期。
2016年8月,英特尔花了三四亿美元买下专注于打造深度学习专用于硬件的加州创企Nervana,收购后不久,前Nervana CEO就被晋升为英特尔AI事业部总负责人,首款采用台积电28nm工艺的深度学习专用芯片Lake Crest在2018年量产,并宣称性能是当时最快的GPU的10倍。
对于云端AI芯片推理,英特尔在拉斯维加斯举行的CES上透露,它正在与Facebook就Nervana神经网络处理器NNP-I的推理版本密切合作。NNP-I将是一个片上系统(SoC),内置英特尔10nm晶体管,并将包括IceLake x86内核。

今年4月,高通宣布推出Cloud AI 100加速器,将高通的技术拓展至数据中心,预计将于2019年下半年开始向客户出样。
据悉,这款加速器基于高通在信号处理和功效方面的技术积累,专为满足急剧增长的云端AI推理处理的需求而设计,可以让分布式智能从云端遍布至用户的边缘终端,以及云端和边缘终端之间的全部节点。

高通产品管理高级副总裁Keith Kressin称:“高通CloudAI 100加速器将为当今业界的数据中心的AI推理处理器树立全新标杆——无论是采用CPU、GPU和/或FPGA的哪种组合方式来实现AI推理的处理器。”
此外,他还介绍说,高通目前正处在优势地位支持完整的从云端到边缘的AI解决方案,所有的AI解决方案均可与具备高速率和低时延优势的5G实现连接。
相比上面对云和数据中心市场野心勃勃的芯片巨头们,下面这些跨界玩家的心思可就相对“单纯”很多。
这些中美互联网巨头的目标不是直接与NVIDIA、英特尔或AMD竞争,而是向他们自己的云客户提供强大的算力,减少对传统芯片制造商的依赖。
他们自研芯片的选择也不完全一样,谷歌、亚马逊等选择专用芯片(ASIC)的路线,而微软等则致力于使用现场可编程门列(FPGA)。
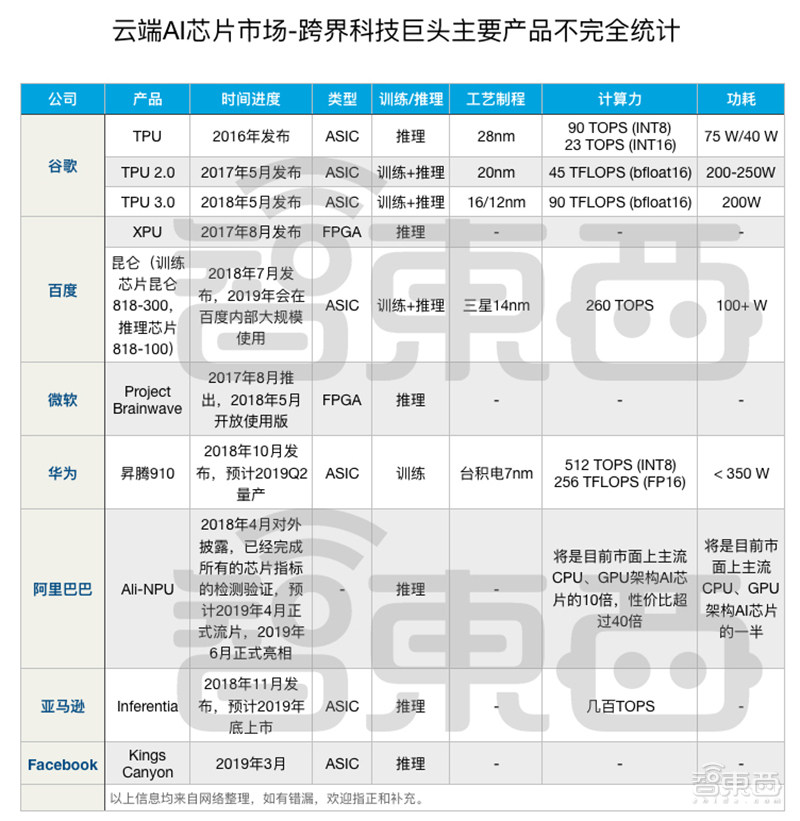
作为最早开始做AI相关研发的科技公司之一,谷歌亦是试水专用AI芯片的先锋,最早验证ASIC可以在深度学习领域替代GPU。
谷歌于2016年推出了自己开发的AI芯片Tensor Processing Unit(TPU),现已进入第三代,为谷歌的语音助理、谷歌地图、谷歌翻译等各种AI应用提供算力支撑。最初设计的TPU用于深度学习的推理阶段,而新版本已能用于AI训练。
谷歌声称,使用32种最好的商用GPU训练机器翻译系统要一天的时间,相同的工作量需要在8个连接的TPU上花费6个小时。
谷歌目前只在自己的数据中心内运营这种设备,没有对外出售。不过最近,谷歌表示将允许其他公司通过其云计算机服务购买其TPU芯片。
谷歌TPU在谷歌对外服务的市场是有限制的,TPU只能用与和运行Google TensorFlow AI框架,用户没办法使用它们来训练或运行使用Apache MxNet或Facebook的PyTorch构建的AI,也不能将它们用于GPU占据着至高无上地位的非AI HPC应用程序中。
但谷歌对此表示满意,因为它将TPU和TensorFlow视为其全面的AI领导力的战略。针对其软件进行了优化的软件针对其软件进行了优化,可以构建强大而耐用的平台。
今年开年的新消息是谷歌在印度班加罗尔成立了新的芯片团队gChips,并从英特尔、高通、博通和NVIDIA等传统芯片公司那里大举招兵买马,至少招募了16名技术老兵。
去年5月,微软AI芯片Brainwave开放云端测试版,称Project Brainwave计算平台使用的FPGA芯片为实时AI而设计,比谷歌使用的TPU芯片处理速度快上了5倍(微软AI芯片Brainwave开放云端试用版 比TPU快5倍)。微软Azure执行副总裁Jason Zander还曾表示,微软Azure实际上设计了许多自研芯片,用于数据中心。

不得不承认,国内科技巨头给芯片起名字,那文化水平高出国外不止一个Level。
百度给云端AI芯片命名的“昆仑”是中国第一神山,相传这座山的先主,被古人尊为“万山之宗”、“龙脉之祖”,嫦娥奔月、西游记、白蛇传等家喻户晓的神话传说都与此山有所关联。
华为云端AI芯片的“昇腾”则取超脱尘世、上升、器宇轩昂之义,颇受文人墨客的喜爱。
百度和华为都是国内早早跨界造芯的科技公司。早在2017年8月,百度就在加州Hot Chips大会上发布了一款256核、基于FPGA的云计算加速芯片,合作伙伴是赛灵思。华为做芯片就更早了,2004年就成立半导体公司海思,只不过以前都是做终端的芯片解决方案。
2018年下半年,以它们为代表的新一轮造芯势力吹响了中国云端AI芯片冲锋的号角。
百度是国内较早试水造芯的科技巨头,最早在2010年就开始用FPGA做AI架构的研发,2011年开展小规模部署上线年打破几千片的部署规模,2017年部署超过了10000片FPGA,百度内部数据中心、无人驾驶系统等都在大规模使用。
2017年8月,百度发布了一款256核、基于FPGA的XPU芯片,这款是和赛灵思合作的,核心很小,没有缓存或操作系统,效率与CPU相当。
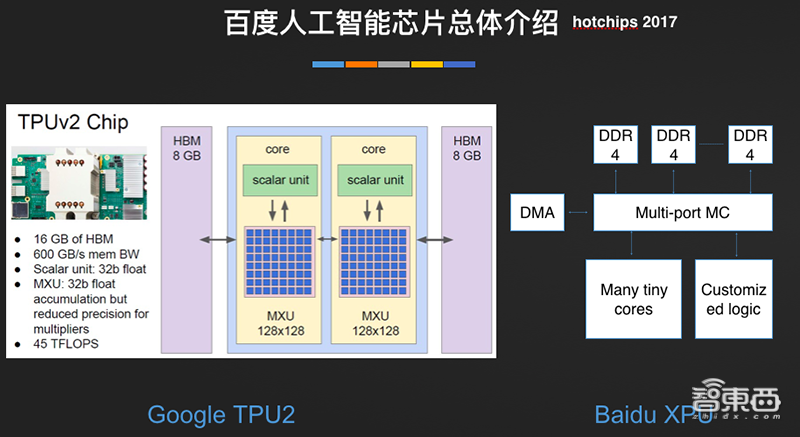
随后在2018年7月举办的百度AI开发者大会上,百度宣布当时业内的算力最高的AI芯片——昆仑。
参数方面,昆仑芯片由三星代工,采用14nm工艺,内存带宽达512GB/s,核心有数万个,能在100W以上的功耗提供260 TOPS的算力。
以NVIDIA最新图灵(Turing)架构的T4 GPU为对比,T4最大功耗为70W,能提供的最高算力也是260 TOPS,但这款GPU比昆仑芯片的发布晚了2个月,并且初期并没有在中国开售。百度主任架构师欧阳剑在今年的AI芯片创新峰会上透露,今年“昆仑”会在百度内部大规模使用。

华为的云端AI芯片昇腾910更是直接在发布现场和NVIDIA与谷歌正面PK。昇腾910直接用起了最先进的7nm工艺,采用华为自研的达芬奇架构,最大功耗350W。华为打的旗号是截止到发布日期“单芯片计算密度最大的芯片”,半精度(FP16)运算能力达到256 TFLOPS,比NVIDIA V100的125 TFLOPS足足高了一倍。
徐直军甚至表示,假设集齐1024个昇腾910,会出现“迄今为止全球最大的AI计算集群,性能达到256P,不管多么复杂的模型都能轻松训练。”这个大规模分布式训练系统,名为“Ascend Cluster”。

落地方面,百度 称其昆仑将于今年年内在百度数据中心大规模使用,华为的昇腾910原计划在今年Q2上市,现在在贸易战的背景之下,不知道会不会延迟。
作为中美云计算市场的龙头,阿里巴巴和亚马逊虽然稍微迟到,但绝不会缺席。
两家的研发目的都很明确,是未解决图像、视频识别、云计算等商业场景的AI推理运算问题,提升运算效率、降低成本。
阿里巴巴达摩院去年4月宣布,Ali-NPU性能将是现在市面上主流CPU、GPU架构AI芯片的10倍,制造成本和功耗仅为一半,性价比超40倍。同月,阿里全资收购大陆唯一的自主嵌入式CPU IP核公司中天微。
新进展发生在9月,阿里将中天微与达摩院自研芯片业务合并,整合成一家芯片公司平头哥。研发Ali-NPU的重任由平头哥接棒,首批AI芯片预计2019年下半年面世,将应用在阿里数据中心、城市大脑和无人驾驶等云端数据场景中。未来将通过阿里云对外开放使用。
在模拟验证测试中,这款芯片的原型让铺设阿里城市大脑的硬件成本节约了35%。但此后,阿里几乎未再发出相关进展的声音。
亚马逊的云AI芯片Inferentia是去年11月在拉斯维加斯举行的re:Invent大会上公布的。
这款芯片的技术源头要追溯到亚马逊在2015年初花费3.5亿美元收购的以色列芯片公司Annapurna Labs。按照官方介绍,每个Inferentia芯片提供高达几百TOPS的算力,多个AWS Inferentia芯片可形成成千上万的TOPS算力。该芯片仍在开发中,按预告,这款芯片将于2019年底上市。

除了买下相对成熟的芯片公司外,招兵买马也是常备之选。Facebook的造芯计划在去年4月初露端倪,官网上发布了招聘ASIC&FPGA设计工程师的广告,用于组建芯片团队。3个月后,美媒彭博社报道称,Facebook挖走谷歌高级工程师主管Shahriar Rabii担任副总裁兼芯片负责人。
Facebook首席AI科学家、最新图灵奖获得者Yann LeCun在接受媒体采访时透露,其造芯主要是未来满足对网络站点进行实时视频监控的需求。
而等到今年1月时,英特尔在全球消费电子展(CES)上表示,正与Facebook合作开发一款新的AI芯片,用于加速推理,并力争在今年下半年开发完成。
AI的复兴颠覆了以往由英特尔、AMD、高通等顶级芯片公司carry全产业的稳定局面,为新的一批芯片创业者创造了机会。
一些初创公司希望从头开始创建一个新平台,一直到硬件,专对于AI操作来优化。希望能够通过这样做,它能够在速度,功耗,甚至有可能是芯片的实际尺寸方面超越GPU。
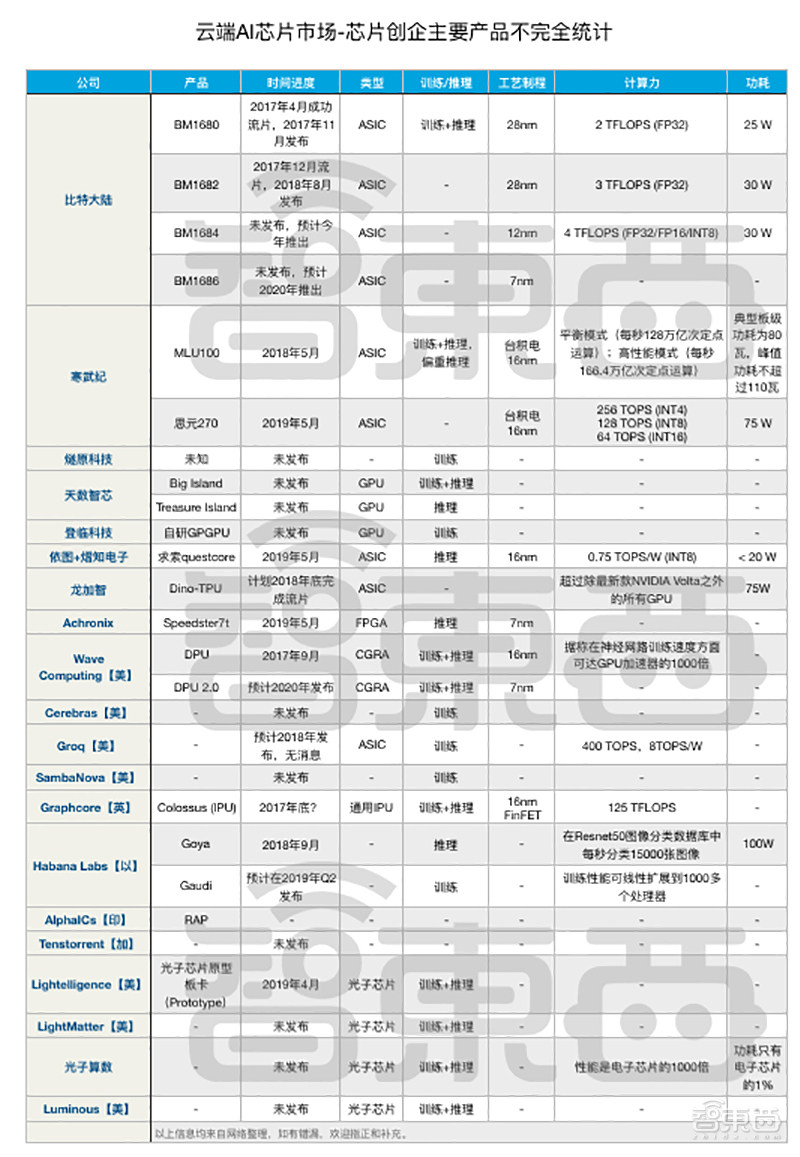
比特大陆作为矿机芯片老大业界闻名,但在过去一年的比特币大退潮中,比特大陆首当其冲陷入舆论漩涡,上市计划未能如期实现。
这家2013年成立的公司,在2015年就启动AI芯片业务。继2017年推出第一代28nm云端AI芯片产品BM1680后,它在2018年第一季度发布第二代BM1682,迭代时间仅9个月。
按照比特大陆去年公布的造芯计划,12nm的云端芯片BM1684应在2018年年底推出,BM1686将在2019年推出,很可能采用7nm制程,不过这两款芯片都姗姗来迟。
寒武纪曾因嵌在华为首款手机AI芯片中麒麟970中的神经网络处理器(NPU)成功打响知名度,成为国内外AI芯片创企中的当红炸子鸡,在经历A、B两轮融资后,整体估值约25亿美元(约170多亿人民币)。
2018年5月,寒武纪正式对外发布第一代云AI芯片MLU100,据称可以以更低的功率提供比NVIDIA V100更好的性能。其客户科大讯飞曾披露测试结果,称MLU100芯片在语音智能处理的能耗效率领先国际竞争对手的云端GPU方案5倍以上。
一年后,其第二代云端AI芯片思元270芯片未发先热,部分性能被知乎网友曝光,峰值性能和功耗都基本与NVIDIA Tesla T4基本持平,业内传闻寒武纪可能在低精度训练领域有所突破。该芯片不出意外地话将于近期发布。

令人稍感意外的玩家是国内计算机视觉(CV)四小龙之一依图科技。今年5月,依图发布了与AI芯片创企熠知电子(ThinkForce)联合开发的首款云端AI芯片求索questcore。
熠知电子是一家低调但不可以小看的上海AI芯片创企,于2017年获依图科技、云锋基金、红杉资本、高瓴资本的4.5亿元人民币A轮融资。其核心成员来自IBM、AMD、英特尔、博通、Cadence等半导体巨头,均有十年以上的芯片行业从业经历。
这款云端深度学习推理定制化SoC芯片采用16nm制程和拥有自主知识产权的ManyCore架构,据称最高能提供每秒15 TOPS的视觉推理性能,仅针对INT 8数据(8 位整数数据类型)进行加速,最大功耗仅20W,比一个普通的电灯泡还小。
依图表示,开发这款芯片不是想追求NVIDIA那样几百个T的算力,而是看重高计算密度。
和前述的跨界科技巨头们一样,依图芯片商用的第一步也是结合其自身软硬件和解决方案打包出售,不会单独售卖,第二、三代产品也都在筹备中。

上海的热门造芯新势力还有燧原科技。它可以说是国内最年轻的AI芯片造芯者,2018年3月成立,获得由腾讯领投的3.4亿元人民币Pre-A轮融资,主攻云端AI加速芯片及相关软件生态的研发投入。这是腾讯第一次投资国内AI芯片创企。
燧原科技的创始团队大多数来源于于AMD,其创始人赵立东此前曾任职于 AMD 中国,后又赴锐迪科(现与展讯合并为紫光展锐)任职总裁。
2019年6月6日,燧原科技宣布新一轮3亿元人民币融资,由红点创投中国基金领投,海松资本、腾讯等投资。其深度学习高端芯片的神秘面纱尚未揭开。
和前几位玩家不同的是,天数智芯和登临科技选择的是直接与NVIDIA对标的通用GPU(GPU)。
在国内,尚无能与NVIDIA分庭抗礼的GPGPU公司,这对创企而言是个值得切入的机会。
两家公司的造芯阵容都很成熟,天数智芯的硬件团队基于AMD在上海和硅谷的GPU团队,登临科技的创始团队也是在GPU行业多年的老将。
目前天数智芯的高中低端GPGPU产品都在研发中,其高端芯片Big Island将同时支持云端推理和训练。登临科技的GPGPU处理器也已通过FPGA验证,第一代产品Goldwasser的设计已完成,计划在今年年底前可供客户测试使用。
还有一家创企名为龙加智,创立于2017年7月,由挚信资本和翊翎资本领投,致力于研发TPU芯片。
为了满足对低时延、高可靠性和数据安全的需求,龙加智推出新的芯片类型关键任务芯片 (Mission-Critical AI Processor),第一代芯片命名Dino-TPU,最先应用于云端数据中心,算力超过除最新款Nvidia Volta之外的所有GPU,时延仅为Volta V100的1/10,功耗为75W,且独具冗余备份和数据安全保障。
一家去年存在感较强的企业是Wave Computing。这家创企去年收购了老芯片IP供应商MIPS,还推出MIPS开放计划。它的累计融资达到1.17亿美元。
其主要优势是使得硬件灵活性更好地适配于软件,在可编程性(或通用性)和性能方面达到很好的综合平衡,降低AI芯片开发门槛,不会受到GPU等加速器中存在的内存瓶颈的影响。
Wave的第一代DPU采用16nm制程工艺,以6 GHz以上的速度运行,已经落地商用。据其高级副总裁兼CTO Chris Nicol介绍,新一代7nm DPU将引入MIPS技术,并采用高带宽内存HBM(High Band Memory),预计在明年发布。
还有一家十分神秘的创企Cerebras System,它于2016年在美国加利福尼亚创办。即便它至今未发布任何一个产品,这并不妨碍它常常被与芯片巨头们相提并论。
Cerebras的创始团队大多来自芯片巨头AMD。其联合创始人兼首席CEO安德鲁·费尔德曼(Andrew Feldman)此前曾创办SeaMicro,这是一家低功耗服务器制造商,在2012年被AMD以3.34亿美元收购。此后,费尔德曼花了两年半的时间爬上了AMD的副总裁之位。
在三轮融资中,Cerebras筹集了1.12亿美元,其估值已飙升至高达8.6亿美元。如今,Cerebras仍处于秘密模式,据相关的人偷偷表示,其硬件将为“训练”深度学习算法量身定制。
2017年4月成立的Groq创始团队更是抢眼,来自谷歌TPU十人核心团队中的8人。这家创企一出场就雄心勃勃,官网显示器芯片算力将能达到400 TOPS。
其A轮融资由谷歌母公司Alphabet的风险投资部门Google Venture(GV)领投,这是GV首次对AI芯片公司做投资。今年4月,英特尔投资宣布向14家科技勇于探索商业模式的公司新投资总计1.17亿美元,SambaNova Systems也在名单中。
最被看好的是一家资金雄厚的英国独角兽Graphcore,成立于2016年,估值达到17亿美元,累计融资3.12亿美元。这家创企堪称巨头收割机,投资阵容很强大,包括红杉资本、宝马、微软、博世和戴尔科技。
这家公司打造了一款专为机器智能工作负载而设计的智能处理单元(IPU),采用支持片上互连和片上存储,从边缘设备扩展到用于数据中心训练和推理的“Colossus”双芯片封装。
Graphcore在官网上如是写道:我们的IPU系统旨在降低在云和企业数据中心加速AI应用程序的成本,与目前最快的系统相比,将训练和推理的性能提高多达100倍。

另一家2016年成立的以色列创企Habana Labs,在去年9月的AI硬件峰会上宣布已经准备推出其首款用于推理的AI芯片Goya,它显示了在Resnet50图像分类数据库中每秒分类15000张图像的吞吐量,比NVIDIA的T4设备高出约50%,延迟时间为1.3ms,功耗仅为100 W。
其最新7500万美元B轮融资(2018年12月)由英特尔风险投资公司领投,资金将部分用于研发第二款芯片Gaudi,该芯片将面向训练市场,据称训练性能可线多个处理器。
印度AlphaICs公司也是在2016年成立,正在设计AI芯片并致力于AI 2.0,希望能够通过该系列新产品实现下一代AI。
AlphaICs的一位联合发起人之一是有“奔腾芯片之父”称号的Vinod Dham,他与一些年轻的芯片设计师们合作打造了可执行基于代理的AI协处理芯片——RAP芯片。
Dham表示,AlphaICs芯片在处理速度上相较竞争对象更有优势,并称当前我们正真看到的大多属于弱AI,而他们能够被称之为“强AI”。
按照Dham的说法,RAP芯片有望在2019年年中推出,“希望为真正的AI创造一个大爆炸”。
Tenstorrent是位于加拿大多伦多的创企,由两位AMD前工程师Ljubisa Bajic和Milos Trajkovic创办,核心团队大多来自NVIDIA和AMD,研发专为深度学习和智能硬件而设计的高性能处理器。
去年早一点的时候,此公司获得来自Real Ventures的种子轮投资,不过至今仍处于秘密模式。
在面向云和数据中心领域的硬件势力中,一支特别的战队正受到国内外科技巨头的青睐,它就是光子AI芯片。
和常规芯片不同,这些芯片采用光子电路来代替电子传输信号,他们比电子电路拥有更高的传输速度、更低的延迟和更高的吞吐量。
2016年,MIT研究团队打造了首个光学计算系统,该成果于2017年以封面文章的形式发表在顶级期刊Nature Photonics杂志。正是这篇论文,在全世界内启发更多人投入到光子AI芯片的研发之中。
Lightelligence称光子电路(Photonic Circuits)不仅能在云计算领域作为CPU的协处理器加速深度学习训练和推理,还能用于要求高效低能耗的网络边缘设备。
今年4月,Lightelligence宣布成功开发出世界第一款光子芯片原型板卡(Prototype),其光子芯片已与谷歌、Facebook、AWS、BAT级别的客户接洽。
LightMatter同样重点面向大型云计算数据中心和高性能计算集群,他们曾打造出2个早期的芯片,其中一个芯片包含超过十一个晶体管。
受MIT那篇论文的启发,2017年,国内第一家光子AI芯片创企光子算数由来自由清华大学、北京大学、北京交通大学等10所高校的博士生创立。
这家公司在2018年9月获得天使轮融资,据称其光子芯片的性能是电子芯片的1000倍,而功耗只有电子芯片的1%。
Luminous目前仅有7位成员,但它的胃口可不小,目标是为包含谷歌最新的Tensor Processing Unit AI芯片的3000块电路板创建一个替代品。它们采用的方法借鉴了其联合创始人Mitchell Nahmias在普林斯顿大学的早期神经形态光子学工作。
现在这几家创企共同存在的问题是,不清楚多久能发布首款量产的光子AI芯片,以及这些芯片的实际应用效果能否真正取代电子芯片的位置。
如今切入云AI芯片市场的玩家已经有数十家,不过由NVIDIA主导、多家半导体巨头分食的软硬件和服务市场大体格局依然较为稳定,产生新的格局变动绝非一件易事。
半导体巨头能轻松实现十倍、百倍的产能,而创企很难在创业初期就做到这一点。现在的创企多为IC设计厂商,如果他们想要成为像英特尔、三星那样“自给自足”的公司,在大多数情况下要花数十亿美元不止。
经过2015-2016年的半导体行业整合浪潮后,近两年半导体并购潮正在逐渐“退烧”,大公司对芯片创企的投资或收购行动会更加谨慎。
从当前市场上较受关注的云AI芯片公司来看,它们的研究团队多是在芯片巨头有超过十年从业经历的行业老兵,而且往往有带头研发出相关成功产品的经验。
无论是半导体巨头还是跨界造芯的科技巨头,大多数都在走两种路径,一是投资并购成熟的芯片公司,另一种就是从挖走其他大公司的芯片高管。
英特尔研究院院长宋继强曾经向智东西表示,AI芯片的未来一定是多样化,不一样的种类的产品满足多种功耗、尺寸、价钱的要求,AI一场马拉松,现在这一场比赛才刚刚开始。
现阶段,入局云AI芯片领域的绝大多数巨头和创企都在打创新的招牌,包括创新的架构、存储技术和硅光技术等。
由于对推动深度学习的新型计算资源的需求激增,许多人认为这是初创企业从巨头和投资机构手中争取资金的难得机会。
尽管玩家正在增多,打出的旗帜也趋于多样化,但就目前而言,真正落地量产的创新硬件还很有限。云端AI芯片面临的困境仍有很多,比如计算机体系结构都会存在的摩尔定律难以维系与半导体器件方面的瓶颈。
研发芯片的过程在大多数情况下要数年时间,目前大部分硬件仍在开发中或在早期试验计划中进行。因此,很难预测哪些企业会实现承诺的性能。
总体来看,云端AI芯片市场正逐渐分成,以英伟达、英特尔等为代表的半导体巨头,以谷歌、华为等为代表的中美科技巨头,和以寒武纪、Groq等为代表的芯片创企。其中,半导体巨头和芯片创企面向主攻通用芯片,而跨界造芯的科技巨头以及AI创企依图暂时不对外直接销售。
从应用领域来看,尽管GPU的高能耗遭到业界慢慢的变多的吐槽,但因其无与伦比的并行运算能力,使得云端AI训练领域至今还没出现能与NVIDIA GPU分庭抗礼的玩家。挑战这一领域的玩家主要是传统芯片巨头和创企,跨界的科技巨头有谷歌、百度和华为,主要是采用的架构是通用GPU和ASIC。
在更注重能耗、时延、成本、性价比等综合能力的云端AI推理领域,入局的玩家相对更多,FPGA和ASIC的优势相对高于GPU。拥有全面AI芯片布局的英特尔势头正猛,别的玩家也不遑多让,中美几大互联网巨头基本上全部加入战局,但部分巨头的芯片研发进展尚未可知。
关于提升造芯实力,多数半导体巨头和科技巨头均选择了投资、并购和挖芯片大牛的捷径,从而直接得到成熟芯片团队的辅助,快速补足人才和业务的空缺。而对于创企来说,获得投资界青睐的基本都具备两大因素——富有经验的创始团队和拥有创新技术的产品,从落地进程来看,我国芯片创企的步伐可以排在世界前列。
就目前来看,绝大多数AI应用仍然依赖于在云端的训练和推理,在训练领域,NVIDIA稳固的生态体系依然是难以撼动的一座高山,在推理领域,更是群雄逐鹿能者胜。随着AI更广泛地落地到各行各业,云端AI芯片市场也会获得更大的增长空间,但这篇市场未必容得下这么多的玩家,资金、器件瓶颈、架构创新、适配快速改变的AI算法以及构建ECO都是摆在这一些企业面前的难题。什么是完全适合云端训练和推理的AI芯片形态,也尚未出现统一的结论。